
In today’s complex digital ecosystem, a reactive approach to cybersecurity is a recipe for disaster. A single security incident can lead to devastating financial losses, reputational damage, and operational chaos. This is where mastering incident response best practices becomes non-negotiable. It is not just about having a plan; it is about building a resilient, agile, and intelligent defense system that can anticipate, withstand, and quickly recover from sophisticated attacks.
This guide moves beyond generic advice to provide a detailed roundup of eight critical practices that form the backbone of a modern incident response strategy. We will explore actionable steps, real-world examples, and the specific frameworks and tools needed to transform your incident response from a theoretical document into a battle-tested operational capability. Whether you are a DevOps engineer refining a deployment pipeline, a product manager safeguarding user data, or a security team fortifying enterprise defenses, these insights are essential. You will learn how to develop a comprehensive plan, establish clear communication protocols, and implement a cycle of continuous improvement. Following these incident response best practices will help you stay ahead of threats and secure your operations.
1. Develop a Comprehensive Incident Response Plan
An incident response plan (IRP) is the single most critical document in your cybersecurity arsenal. It serves as a detailed, step-by-step guide that dictates exactly how your organization will act during a security crisis. Without a well-defined plan, teams react with confusion and delay, which allows threats to escalate, data loss to increase, and reputational damage to spiral. A comprehensive IRP is foundational to effective incident response best practices, transforming chaotic reactions into a coordinated, strategic defense.
This plan isn’t just a technical document for your IT team; it’s an organizational playbook. It must clearly define roles, responsibilities, and communication pathways across departments. For example, your plan should specify who has the authority to disconnect a critical system, who contacts law enforcement, and how your communications team will inform customers, as seen in Maersk’s successful recovery from the devastating NotPetya attack.
Key Components of an Effective IRP
A robust IRP is a living document, not a “set it and forget it” file. To ensure its effectiveness, it must be both comprehensive and accessible, even if your primary network is compromised.
- Stakeholder Involvement: Develop the plan with input from legal, HR, communications, and executive leadership. This ensures all business, regulatory, and public relations requirements are met.
- Tiered Response Procedures: Don’t use a one-size-fits-all approach. Create specific playbooks for different incident types, such as malware infections, DDoS attacks, or data breaches. Each requires a unique set of actions.
- External Contact List: Maintain an up-to-date list of external contacts, including cybersecurity insurance providers, forensic investigators, legal counsel, and law enforcement agencies.
- Regular Drills and Updates: Test the plan through tabletop exercises and simulations at least twice a year. Update it based on these drills, lessons learned from real incidents, and the evolving threat landscape.
To help your team quickly determine the correct initial response path, a decision tree can guide them through the first critical steps.
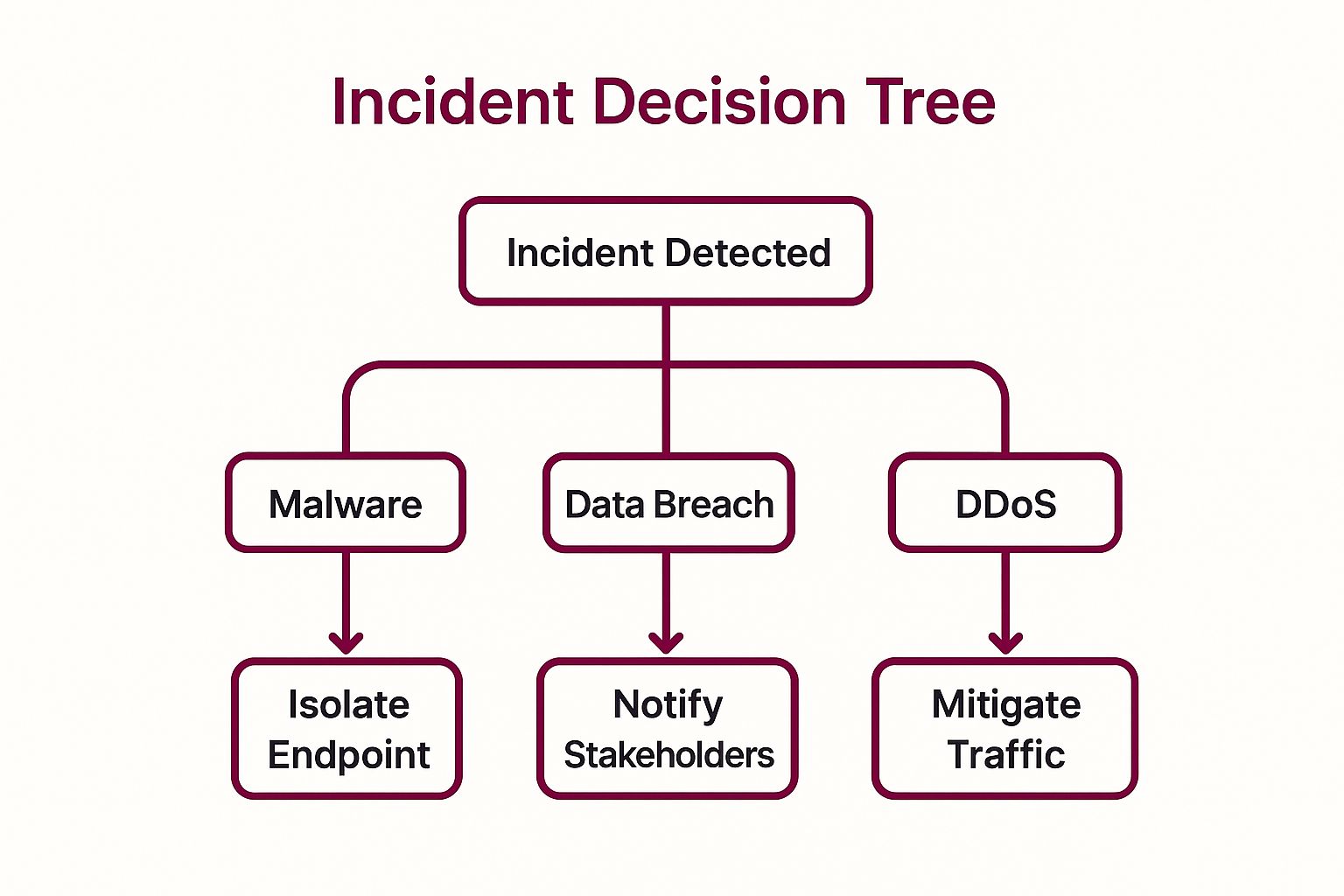
This flowchart illustrates how the initial response diverges significantly based on the type of incident detected, ensuring that the most critical first action is taken immediately. For organizations seeking to build a robust security posture, a well-structured IRP is the first and most important step. You can discover more advanced strategies for securing your applications in our security article category.
2. Establish and Train a Dedicated Incident Response Team
While a plan is critical, it’s the people who execute it. An effective incident response team (IRT), sometimes called a Computer Security Incident Response Team (CSIRT), is a specialized group of individuals responsible for responding to security incidents. This team acts as the organization’s “first responders” for cyber crises, bringing specialized skills to bear when seconds count. Having a pre-defined, trained team is a core tenet of incident response best practices, ensuring that skilled personnel are ready to act decisively instead of scrambling to assign roles in the middle of an attack.
This team isn’t just an ad-hoc group of IT staff; it’s a cross-functional unit. It requires a blend of technical, legal, and communication expertise to manage an incident holistically. For instance, tech giants like Microsoft and financial institutions like JPMorgan Chase have invested heavily in dedicated, 24/7 incident response teams. These teams combine deep technical knowledge for threat hunting with the business acumen needed to make critical operational decisions, demonstrating the value of a prepared, multi-disciplinary approach.

Key Components of an Effective IRT
A high-performing IRT is built through careful selection, continuous training, and clear authority. The goal is to create a cohesive unit that can function under extreme pressure.
- Cross-Functional Membership: The team should include core members from IT security and operations, alongside representatives from legal, HR, communications, and executive leadership. This ensures all facets of an incident, from technical containment to regulatory disclosure, are managed concurrently.
- Clear Roles and Authority: Define specific roles (e.g., Incident Commander, Lead Analyst, Communications Liaison) and grant them the authority to make critical decisions, such as isolating a network segment or taking a system offline.
- Continuous Training and Drills: Regularly train the team on the latest attack vectors, forensic tools, and response techniques. Conduct tabletop exercises and realistic simulations to build muscle memory and identify gaps in your response plan.
- External Expertise on Retainer: For small to mid-sized organizations, maintaining a full-time, in-house team may be unfeasible. In these cases, establishing a retainer with a third-party incident response firm like Verizon’s a proactive measure that guarantees access to expert help when needed.
Building this team is a foundational investment in your organization’s resilience. It ensures that when an incident occurs, you have a prepared, capable, and authorized group ready to minimize damage and accelerate recovery. You can find more strategies for building a strong security culture in our security article category.
3. Implement Continuous Monitoring and Detection Systems
Effective incident response best practices demand that you detect threats as early as possible. Continuous monitoring and detection systems are the bedrock of this capability, providing real-time visibility across your entire IT environment. These systems are not just passive observers; they are your digital sentinels, actively hunting for anomalies and malicious activity. By integrating technologies like SIEM (Security Information and Event Management) and EDR (Endpoint Detection and Response), you can shorten the time between compromise and detection, drastically reducing an attacker’s window of opportunity.
The infamous Target data breach serves as a stark reminder of what happens when monitoring fails; the initial intrusion went undetected for weeks, allowing the breach to escalate dramatically. In contrast, modern platforms like CrowdStrike Falcon were instrumental in identifying the complex SolarWinds supply chain attack, showcasing the power of proactive, continuous visibility. These systems transform security from a reactive, post-mortem exercise into a proactive, real-time defense.

Key Strategies for Effective Monitoring
Implementing a successful monitoring program involves more than just deploying tools; it requires a strategic, iterative approach to ensure comprehensive coverage without overwhelming your team with noise.
- Prioritize Critical Assets: Begin by focusing your monitoring efforts on your most valuable assets, such as critical servers, databases, and applications. Expand coverage outward as you mature your capabilities.
- Tune Detection Rules: Actively manage and refine your detection rules and alert thresholds. This crucial step minimizes false positives, ensuring your security team can focus on legitimate threats instead of chasing ghosts.
- Integrate Diverse Data Sources: Pull telemetry from multiple sources, including network traffic, endpoint activity, cloud logs, and application logs. A holistic view is essential for connecting disparate events into a coherent attack narrative.
- Leverage Threat Intelligence: Enrich your detection systems with up-to-date threat intelligence feeds. This provides context, helping you identify known indicators of compromise (IOCs) and tactics from active threat actors.
By adopting these strategies, you can build a vigilant and responsive security posture. Integrating these practices into your development lifecycle is also key; you can explore related concepts in our continuous integration article category.
4. Prioritize Incident Classification and Triage
Once an incident is detected, the immediate challenge is to understand its significance. Incident classification and triage is the systematic process of categorizing security events based on their severity, impact, and urgency. This critical step ensures that limited response resources are directed at the most pressing threats first, preventing teams from wasting valuable time on low-risk alerts while a major breach unfolds. Effective classification transforms a flood of raw alerts into a prioritized queue of actionable incidents, forming a core pillar of modern incident response best practices.
This process is not just about labeling threats; it’s about making rapid, informed decisions that align technical response with business priorities. A well-executed triage system prevents “alert fatigue” and ensures that every incident receives the appropriate level of attention. For example, government agencies use classification systems like the Traffic Light Protocol (TLP) to dictate how sensitive information is shared, while healthcare organizations classify events based on potential HIPAA breach impact, ensuring regulatory compliance is considered from the outset.
Key Components of Effective Classification and Triage
A strong classification framework must be simple enough to be applied quickly under pressure but robust enough to accurately gauge an incident’s potential damage. It requires a clear, documented methodology that everyone on the response team understands.
- Establish Clear Criteria: Develop a simple matrix or set of rules based on data sensitivity, system criticality, threat type, and potential business impact. This removes guesswork and promotes consistency.
- Train Your Team: All personnel involved in the initial response must be thoroughly trained on the classification criteria. Everyone should be able to quickly and accurately categorize common incident types.
- Automate Where Possible: Use your security information and event management (SIEM) or security orchestration, automation, and response (SOAR) tools to automate initial classification based on predefined rules, reducing human error and speeding up the process.
- Allow for Re-escalation: An incident’s perceived severity can change as more information is gathered. Your process must include a clear pathway for reclassifying an incident, either up or down, as the situation evolves.
Documenting the rationale behind each classification decision is crucial. This not only aids in real-time coordination but also provides invaluable data for post-incident reviews, helping you refine your triage process and improve future response efforts. For a deeper dive into protecting your digital assets, explore our comprehensive resources on mobile app security.
5. Maintain Detailed Documentation and Evidence Preservation
Meticulous documentation is the unsung hero of successful incident response. It involves creating a comprehensive, chronological record of every action taken, decision made, and piece of evidence discovered during a security event. In the chaos of a crisis, accurate documentation provides clarity, accountability, and an invaluable resource for post-incident analysis. Proper evidence preservation ensures that this digital trail remains admissible in legal proceedings and useful for forensic investigation, turning a reactive scramble into a methodical, defensible process.
This practice is non-negotiable for any organization facing regulatory scrutiny or potential litigation. For example, forensic evidence from the Target data breach was instrumental in the subsequent criminal prosecutions. Similarly, Anthem’s detailed documentation of its response to a massive 2015 breach was critical for demonstrating due diligence to regulators. Strong documentation and evidence preservation are cornerstone incident response best practices that provide the foundation for legal defense, regulatory compliance, and organizational learning.
Key Components of Effective Documentation and Preservation
To be effective, your documentation process must be rigorous and your evidence handling must be forensically sound. This requires both the right tools and disciplined procedures.
- Establish a Chain of Custody: Implement a formal process for tracking evidence from the moment it is collected. Document who handled the evidence, when, where, and for what purpose to ensure its integrity is legally defensible.
- Use Write-Once Media: Store critical evidence, like disk images or memory captures, on write-once, read-many (WORM) media. This prevents accidental or malicious alteration and proves the evidence has not been tampered with since collection.
- Synchronize System Clocks: Ensure all systems, from servers to firewalls, are synchronized to a single, accurate time source using Network Time Protocol (NTP). This is essential for correlating events across different logs to build a precise incident timeline.
- Document Everything: Record both successful and unsuccessful response actions. Understanding what didn’t work is just as valuable for post-incident review as knowing what did. This detailed record-keeping shares principles with creating a robust deployment rollback plan, where every step is tracked to enable a swift and accurate recovery.
- Consider Legal Privilege: Involve legal counsel early to determine if documentation should be prepared under legal privilege. This can protect sensitive analysis and communications from being discoverable in potential legal disputes.
6. Establish Clear Communication Protocols
During a security incident, technical remediation is only half the battle. How an organization communicates internally and externally can determine whether it maintains trust or suffers irreparable reputational damage. Establishing clear communication protocols is an essential incident response best practice that defines how, when, and what information is shared with employees, customers, regulators, and the public. Without these protocols, conflicting messages, misinformation, and delays can amplify the crisis, as seen in Equifax’s mishandled 2017 breach, which led to significant public backlash and regulatory fines.
Effective communication transforms chaos into managed transparency. Your protocols should detail pre-approved messaging, designated spokespeople, and secure, out-of-band communication channels to ensure messages can be delivered even if primary systems are offline. A well-executed communication strategy, like Maersk’s transparent updates during the NotPetya attack, can preserve stakeholder confidence even in the face of a devastating cyber event.
Key Components of Effective Communication Protocols
A strong communication plan must be proactive, not reactive. It should be built and rehearsed long before an incident occurs to ensure a calm, coordinated, and credible response.
- Pre-Approved Templates: Develop communication templates for various incident scenarios (e.g., data breach, ransomware attack, system outage). Having these drafts ready, pending legal review, dramatically speeds up response time.
- Designated Spokespeople: Clearly define who is authorized to speak on behalf of the company. This typically includes a small group from legal, communications, and executive leadership to ensure messaging is consistent and accurate.
- Secure Communication Channels: Establish primary and backup communication methods (e.g., a dedicated status page, encrypted messaging apps, or an emergency notification system) that are independent of your main corporate network.
- Cross-Functional Training: Ensure your communications and legal teams have a foundational understanding of technical cybersecurity concepts. This helps them translate complex details into clear, accurate public statements.
- Rapid Misinformation Response: Actively monitor social media and news outlets to quickly identify and correct misinformation before it spreads.
By integrating these protocols, you ensure that every stakeholder receives timely, accurate, and appropriate information. Building this level of coordination requires a mature operational mindset, which you can explore further in our articles on DevOps practices.
7. Conduct Regular Testing and Simulations
An incident response plan is only as good as its last test. Without regular, rigorous testing, even the most detailed plan can fail under the pressure of a real crisis. Conducting planned simulations is a core tenet of effective incident response best practices, as it moves your plan from a theoretical document to a battle-tested operational guide. These exercises build crucial muscle memory, allowing your team to act decisively and correctly when every second counts.
Regular testing isn’t about passing or failing; it’s about continuous improvement. It exposes hidden weaknesses in your procedures, clarifies roles, and validates technical tools before a real attacker does. For example, many financial institutions are required by regulators to run sophisticated crisis simulations, and healthcare organizations frequently use tabletop exercises to prepare their teams for the unique challenges of a ransomware attack, ensuring they can protect patient data and maintain critical operations.
Key Components of Effective Testing
To get the most value from your simulations, they must be structured, realistic, and progressively challenging. A well-designed testing program ensures your team is prepared for a wide range of threats.
- Start Simple, Increase Complexity: Begin with straightforward tabletop exercises where stakeholders discuss their responses to a scenario. Gradually move to more complex technical simulations and eventually to full-scale drills that involve your entire organization.
- Use Realistic Scenarios: Base your exercises on current threat intelligence relevant to your industry. A scenario involving a newly discovered vulnerability or a common social engineering tactic will provide more value than a generic, outdated threat.
- Include External Stakeholders: Involve third-party partners like your cybersecurity insurance carrier, forensic investigators, and even local law enforcement. This tests your external communication and coordination procedures in a controlled environment.
- Document and Remediate: Meticulously document all observations and lessons learned during each exercise. Create a formal remediation plan with clear owners and deadlines to address any identified gaps in your plan, tools, or training.
This video provides a great overview of how to structure a tabletop exercise to maximize its effectiveness.
By making testing a routine part of your cybersecurity program, you cultivate a culture of preparedness. You can explore more strategies for building robust testing frameworks in our QA best practices category.
8. Implement Post-Incident Analysis and Continuous Improvement
The final phase of incident response, recovery, is not the end of the process. True cyber resilience is built by learning from every security event, which is why a formal post-incident analysis is one of the most crucial incident response best practices. This process involves a structured review of the entire incident lifecycle to identify successes, failures, and areas for improvement. Without this feedback loop, organizations are doomed to repeat their mistakes, leaving vulnerabilities unaddressed and response capabilities stagnant.
This analysis goes far beyond a simple debrief; it is a forensic examination of your people, processes, and technology under pressure. Its goal is to uncover the root cause of the incident and refine the response playbook for the future. For example, the infamous Morris Worm incident in 1988 directly led to the creation of the first Computer Emergency Response Team (CERT), a model now replicated worldwide. This demonstrates how rigorous post-incident analysis can lead to systemic, industry-wide security enhancements.
Key Components of an Effective Post-Incident Review
A successful review transforms lessons learned into concrete actions. To make this process effective, it must be structured, blameless, and action-oriented, ensuring that insights lead to tangible security improvements.
- Foster a Blameless Culture: The primary goal is improvement, not punishment. Encourage honest and open feedback by assuring all participants that the review is a safe space, free from retribution. This is the only way to get an accurate picture of what truly happened.
- Structured Review Methodology: Use established frameworks like an After-Action Review (AAR) or a Post-Incident Review (PIR). These methodologies provide a consistent structure for discussing what was expected to happen, what actually happened, and why the differences occurred.
- Comprehensive Stakeholder Involvement: Include representatives from every team involved in the response, not just the technical security team. This includes legal, communications, HR, and business unit leaders who can provide diverse perspectives on the incident’s impact and the response’s effectiveness.
- Trackable Action Items: The ultimate output of the review should be a list of specific, measurable, achievable, relevant, and time-bound (SMART) action items. Assign each item to a specific owner with a clear deadline to ensure accountability and track progress toward implementation.
Incident Response Best Practices Comparison
| Item | Implementation Complexity 🔄 | Resource Requirements ⚡ | Expected Outcomes 📊 | Ideal Use Cases 💡 | Key Advantages ⭐ |
|---|---|---|---|---|---|
| Develop a Comprehensive Incident Response Plan | Medium-High: Requires detailed planning and updates | Significant time and personnel for development and maintenance | Consistent, coordinated response; regulatory compliance | Organizations needing structured, company-wide incident handling | Faster recovery; reduced confusion during incidents; clear accountability |
| Establish and Train a Dedicated Incident Response Team | High: Hiring, training, and coordination involved | High investment in skilled personnel and training programs | Faster, expert-driven incident responses, continuous improvements | Companies with complex environments and resources for a dedicated team | Specialized expertise; 24/7 coverage; improved crisis communication |
| Implement Continuous Monitoring and Detection Systems | High: Complex setup and tuning required | Significant technology investment and skilled analysts | Early detection of threats; comprehensive visibility | Organizations seeking real-time security monitoring across IT assets | Early threat detection; automated alerts; compliance support |
| Prioritize Incident Classification and Triage | Medium: Requires defined criteria and training | Moderate: Staff training plus classification tools | Focused resource allocation; timely response prioritization | Environments with limited resources needing prioritized incident handling | Efficient resource use; clear escalation paths; better incident management |
| Maintain Detailed Documentation and Evidence Preservation | Medium: Requires forensic knowledge and processes | Moderate to high: forensic tools and secure storage | Legal evidence preservation; thorough post-incident reviews | Organizations subject to regulatory audits or legal scrutiny | Supports legal actions; regulatory compliance; detailed incident accountability |
| Establish Clear Communication Protocols | Medium: Needs policy creation and coordination | Moderate: Communication tools and trained personnel | Consistent messaging; stakeholder trust; regulatory notifications | Organizations handling public or customer communications during incidents | Maintains trust; reduces confusion; protects sensitive info |
| Conduct Regular Testing and Simulations | Medium-High: Planning and execution of exercises | Moderate to high: time, personnel involvement | Identified gaps; improved readiness and confidence | Any organization aiming to validate and improve incident response | Reveals weaknesses; builds team skills; validates tools and plans |
| Implement Post-Incident Analysis and Continuous Improvement | Medium: Requires structured reviews and follow-up | Moderate: time for analysis and implementing changes | Enhanced response capabilities; prevents recurrence | Organizations committed to long-term security maturation | Drives continuous security improvements; builds institutional knowledge |
Turning Incident Response into a Competitive Advantage
Navigating the complex landscape of cybersecurity requires more than just a defensive mindset; it demands a proactive, strategic approach that transforms potential crises into opportunities for growth. Throughout this guide, we have explored the foundational pillars of effective incident management. These are not isolated tasks but interconnected components of a resilient security ecosystem. Mastering these incident response best practices is the key to elevating your organization’s security posture from a reactive necessity to a genuine competitive differentiator.
The journey begins with preparation. A comprehensive incident response plan acts as your strategic roadmap, while a dedicated, well-trained team serves as the skilled unit ready to execute it. This groundwork is activated by continuous monitoring and detection systems, your digital sentinels that provide the early warnings needed for a swift response. When an alert sounds, a structured approach to incident classification and triage ensures that your team’s efforts are focused where they matter most, preventing resource drain and minimizing initial impact.
From Reaction to Resilience
As an incident unfolds, the emphasis shifts to control and recovery. Meticulous documentation and evidence preservation are not just for forensic analysis; they are critical for legal compliance and for learning from the event. Simultaneously, clear communication protocols are the lifeblood of an effective response, maintaining stakeholder trust, aligning internal teams, and preventing misinformation from compounding the crisis.
However, the true value of an incident response framework is realized long after the immediate threat has been neutralized. The most mature organizations embrace two critical, forward-looking practices:
- Regular Testing and Simulations: Drills and tabletop exercises move your plan from a static document to a living, battle-tested strategy. This is where your team builds muscle memory and uncovers weaknesses in a controlled, low-stakes environment.
- Post-Incident Analysis and Continuous Improvement: A thorough “lessons learned” process is non-negotiable. This feedback loop is what transforms a single incident into an organization-wide improvement, hardening your defenses for the future.
Ultimately, integrating these eight principles into your operational DNA does more than protect your digital assets and customer data. It builds a culture of security awareness, enhances operational efficiency, and safeguards your brand’s reputation. By treating incident response not as an IT problem but as a core business function, you demonstrate a commitment to excellence and reliability that customers, partners, and stakeholders will recognize and value. This commitment turns your response capability from a cost center into a powerful statement about your organization’s resilience and trustworthiness in a volatile digital world.
Ready to close the gap between vulnerability discovery and remediation in your React Native apps? CodePushGo allows you to deploy critical security patches and hotfixes directly to your users’ devices, bypassing app store delays. Supercharge your incident response capabilities by visiting CodePushGo and discover how Over-the-Air (OTA) updates can become a vital part of your security toolkit.


