
From Code Commit to Customer: Navigating Modern Software Deployment
In today’s fast-paced digital environment, the ability to ship reliable software quickly is no longer a luxury, it’s a core business necessity. The gap between writing code and delivering it to users is fraught with potential pitfalls, from integration errors and environment inconsistencies to security vulnerabilities and post-launch bugs. Effective software deployment isn’t just about pushing buttons; it’s a disciplined engineering practice that combines automation, strategy, and security to ensure updates enhance user experience without causing disruption. Adopting robust software deployment best practices is crucial for maintaining a competitive edge, reducing operational risk, and empowering development teams to innovate with confidence.
This guide explores seven essential practices that form the backbone of modern, high-velocity software delivery, providing actionable insights to streamline your release cycles. We will delve deep into foundational strategies like CI/CD and Infrastructure as Code, explore advanced release patterns such as Blue-Green and Canary deployments, and highlight the critical role of security and rollback planning. You will learn how to implement these strategies to build a resilient, efficient, and secure deployment pipeline.
Furthermore, we will examine how these principles extend to the unique challenges of mobile development. Special attention will be given to Over-the-Air (OTA) updates for React Native applications, showcasing how modern tools like CodePushGo can revolutionize the mobile release process. By bypassing traditional app store review delays for certain types of updates, you can deliver critical bug fixes and feature enhancements to your users in near real-time, directly aligning your mobile strategy with the agility of your web services. This comprehensive roundup offers the practical details you need to transform your deployment process from a source of friction into a strategic advantage.
1. Continuous Integration/Continuous Deployment (CI/CD)
At the core of modern, agile software development lies the practice of Continuous Integration and Continuous Deployment (CI/CD). This methodology automates the software release process, transforming it from a risky, manual event into a reliable, frequent, and predictable workflow. Continuous Integration (CI) is the practice of developers frequently merging their code changes into a central repository, after which automated builds and tests are run. Continuous Deployment (CD) extends this by automatically deploying all code changes that pass the testing stage to a production environment.
The fundamental goal is to catch bugs earlier in the development cycle, reduce integration problems, and deliver value to users faster. Companies like Netflix and Amazon have famously leveraged CI/CD to achieve incredible deployment velocities, releasing thousands of updates daily. This approach is a cornerstone of effective software deployment best practices because it establishes a consistent, high-quality delivery mechanism.
Key Stages of a CI/CD Pipeline
A typical CI/CD pipeline automates the journey of code from a developer’s machine to the end-user. This automation ensures that every change undergoes a rigorous, standardized validation process before it is released.
The following infographic illustrates the three fundamental stages that form the backbone of any CI/CD pipeline: code integration, automated testing, and production deployment.
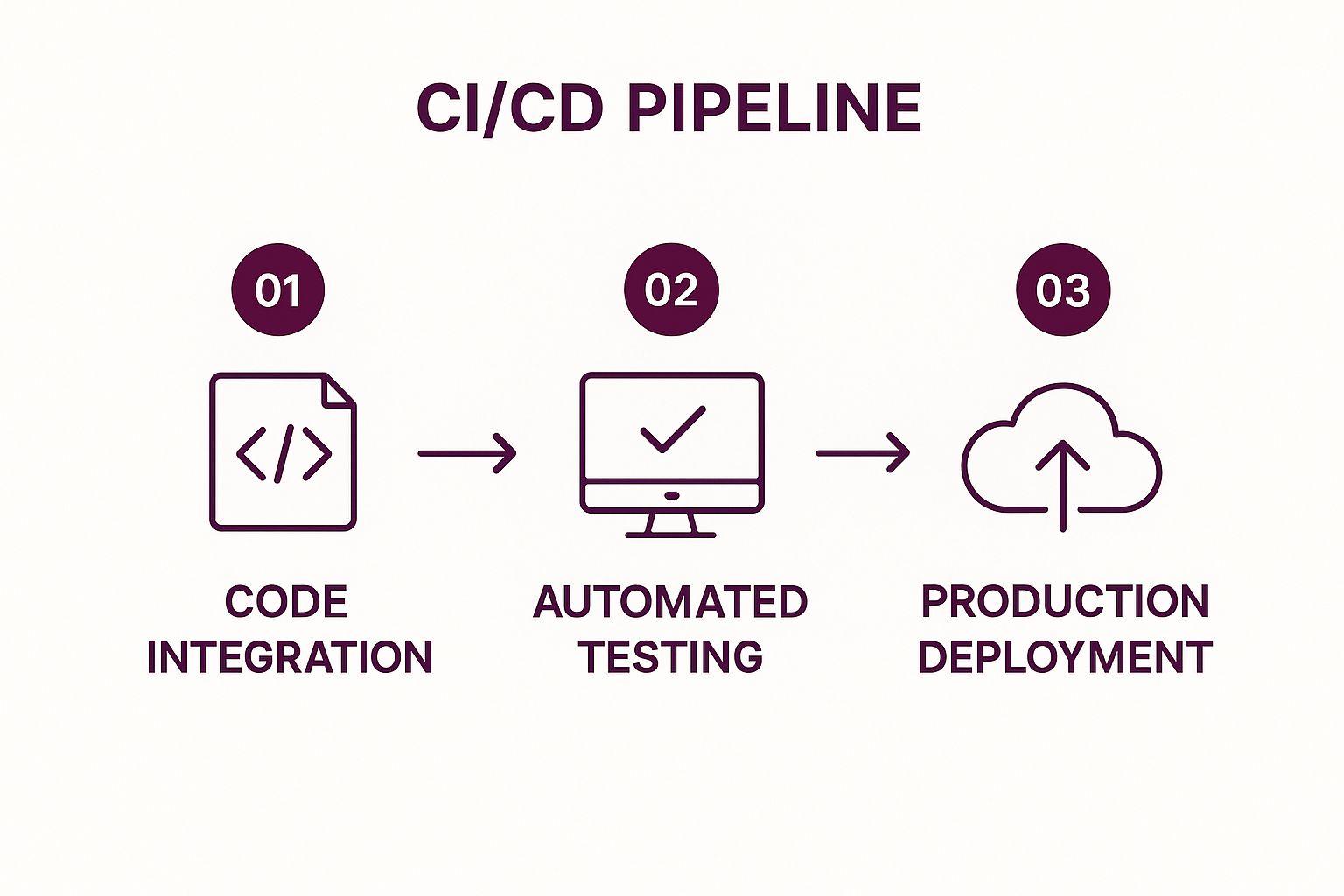
This process flow visualizes how each stage builds upon the last, creating a streamlined path from development to deployment that minimizes manual intervention and risk.
Implementing CI/CD Effectively
Adopting CI/CD requires a strategic approach. It’s not just about tooling; it’s a cultural shift towards automation and rapid feedback.
- Start Simple: Begin with a basic pipeline that automates just the build and initial test stages. You can gradually add more complex steps like security scanning, performance testing, and multi-environment deployments.
- Prioritize Test Coverage: Automated testing is the safety net of CI/CD. Before implementing continuous deployment, ensure you have comprehensive unit, integration, and end-to-end tests to validate code changes automatically and with confidence.
- Use Feature Flags: Decouple deployment from release. Use feature flags to push new code to production in a disabled state. This allows you to test in production safely and roll out features to users without a full redeployment.
- Monitor and Rollback: Implement robust monitoring to track deployment health, application performance, and error rates. Have a clear, automated rollback procedure in place to quickly revert any changes that cause issues.
For those looking to build a robust pipeline from scratch, you can find a comprehensive guide in this CI/CD pipeline tutorial. This approach is essential for any team aiming for speed, reliability, and security in their software delivery lifecycle.
2. Blue-Green Deployment
A powerful strategy for achieving zero-downtime releases and instant rollbacks is the Blue-Green Deployment model. This approach involves running two identical, parallel production environments, conventionally named “Blue” and “Green.” At any given moment, only one environment (e.g., Blue) actively serves live user traffic, while the other (Green) is idle but ready. Blue-Green Deployment reduces deployment risk by allowing a new version of the application to be deployed and fully tested in the idle environment without impacting live users.
This technique is a cornerstone of reliable software deployment best practices, providing a seamless transition from one version to the next. Once the new version in the Green environment is validated, a simple router switch redirects all incoming traffic from Blue to Green. The old Blue environment is then kept on standby, ready for an immediate rollback if any issues arise. This method is favored by high-availability systems like Netflix and Etsy for its simplicity and safety.

This visual representation shows how the router acts as a switch, instantly changing which environment receives live production traffic. This simple yet effective mechanism is the key to achieving a near-instantaneous and low-risk release.
How Blue-Green Deployment Works
The process is methodical and focuses on isolating the new release from live users until it is proven stable. This approach provides a high degree of confidence before making the final switch.
The following video from IBM Cloud provides a clear, animated explanation of how this deployment strategy minimizes downtime and risk during software updates.
This controlled process ensures that deployments are not a source of stress but a routine, predictable part of the development lifecycle.
Implementing Blue-Green Deployment Effectively
A successful Blue-Green strategy requires more than just two server environments; it demands careful planning around data, monitoring, and automation.
- Automate the Switch: The traffic switch should be fully automated using a load balancer or router configuration script. Manual switching is prone to error and negates the speed benefits of this model.
- Manage Database Schema Changes: This is the most complex aspect. Use backward-compatible database changes or employ techniques like parallel data writes to both Blue and Green databases during the transition to ensure data integrity.
- Implement Comprehensive Health Checks: Before flipping the switch, run a complete suite of automated smoke tests and health checks against the Green environment to ensure it’s fully functional and ready to handle production load.
- Monitor Both Environments: During the transition, closely monitor both environments. If the new Green environment shows increased error rates or performance degradation, you can immediately switch traffic back to the stable Blue environment.
3. Canary Deployment
Canary deployment is a strategic, progressive rollout technique where a new version of software is released to a small, controlled subset of users before a full-scale deployment. This method acts as an early warning system, much like the canaries once used in coal mines to detect toxic gases. By exposing the new version to a limited audience first, teams can closely monitor its performance, stability, and impact in a real-world production environment, allowing them to catch and fix issues before they affect the entire user base.
The core principle of canary deployment is risk mitigation. It provides a safety net for releasing new features by limiting the blast radius of potential bugs or performance regressions. Industry leaders like Google and Facebook rely heavily on canary releases for major products like Gmail and the Facebook app, enabling them to innovate rapidly while maintaining high levels of service reliability. This approach is a critical component of modern software deployment best practices because it balances the need for speed with the imperative of stability.
This visual represents how the canary group serves as a live test bed. The insights gained from this small user segment inform the decision to either proceed with a gradual rollout to more users or to initiate an immediate rollback, preventing widespread disruption.
Implementing Canary Deployment Effectively
Successfully adopting canary deployments requires careful planning, precise execution, and a commitment to data-driven decision-making. It’s more than just splitting traffic; it’s about creating a feedback loop.
- Define Clear Success Metrics: Before starting the rollout, establish specific, measurable criteria for success. These Key Performance Indicators (KPIs) should include error rates, application latency, CPU/memory usage, and key business metrics like conversion rates or user engagement. The canary release is considered successful only if it meets or exceeds the performance of the stable version.
- Start with a Small Audience: Begin by routing a very small percentage of user traffic, typically 1-5%, to the new version. This initial group can be selected randomly or targeted based on specific user attributes (e.g., region, device type, or subscription plan).
- Automate Monitoring and Alerting: Implement robust, real-time monitoring and automated alerting for your defined success metrics. Your system should be able to quickly detect anomalies in the canary group and notify the team immediately, enabling a swift response to any issues that arise.
- Use Feature Flags for Granular Control: Combine canary deployments with feature flags to gain even finer control. This allows you to enable or disable specific features within the canary release without a full redeployment, making it easier to pinpoint the source of a problem.
For teams interested in exploring this and other advanced release patterns, you can discover more about different deployment strategies on CodePushGo. A well-executed canary strategy is indispensable for organizations aiming to deliver updates that are both innovative and reliable.
4. Infrastructure as Code (IaC)
A pivotal evolution in cloud computing and DevOps, Infrastructure as Code (IaC) is the practice of managing and provisioning infrastructure through machine-readable definition files. This approach replaces manual processes and interactive configuration tools with code, allowing teams to treat servers, databases, networks, and load balancers just like application code. IaC brings the power of version control, automated testing, and collaboration to infrastructure management. Provisioning is the process of setting up IT infrastructure, and IaC automates this entire lifecycle.

The core objective is to create consistent, repeatable, and scalable environments. By defining infrastructure in code, you eliminate the risk of “configuration drift,” where production and development environments slowly diverge. Companies like Shopify and Airbnb leverage IaC tools like Terraform to manage their vast cloud infrastructure, ensuring stability and rapid scalability. This methodology is a crucial component of modern software deployment best practices because it builds a reliable and automated foundation for the application to run on.
Key Principles of IaC
Adopting IaC involves more than just writing scripts; it’s a strategic shift in how infrastructure is perceived and handled. The goal is to make infrastructure disposable and easily reproducible, reducing dependencies on specific hardware or manual setups.
The following diagram outlines the fundamental cycle of IaC, from defining resources in code to deploying and managing them in the cloud. This loop emphasizes the continuous nature of infrastructure management, where changes are versioned, tested, and applied systematically, just like application software. This iterative process ensures that your infrastructure can evolve safely and predictably alongside your application.
Implementing IaC Effectively
Successfully integrating IaC into your workflow requires careful planning and adherence to established principles. It transforms infrastructure management from a reactive task to a proactive, strategic part of the development lifecycle.
- Use Version Control for All Infrastructure Code: Store all your IaC files (e.g., Terraform, CloudFormation templates) in a Git repository. This provides a full history of changes, enables collaborative peer reviews, and allows for easy rollbacks.
- Implement Infrastructure Testing: Just like application code, infrastructure code should be tested. Use tools like Terratest or Kitchen-CI to validate that your configurations will provision resources correctly and meet compliance and security requirements before applying them.
- Adopt a Modular Approach: Break down your infrastructure into small, reusable, and composable modules. A module for a database should be separate from a module for a web server. This approach, promoted by tools like Terraform by HashiCorp, enhances reusability and simplifies management.
- Regularly Audit and Update: Infrastructure definitions can become outdated. Regularly audit your code to remove unused resources, apply security patches, and update to the latest versions of your cloud provider’s services to prevent security vulnerabilities and optimize costs.
5. Automated Testing and Quality Gates
A deployment pipeline is only as reliable as the quality of the code it delivers. This is where Automated Testing and Quality Gates become indispensable. This practice involves embedding comprehensive, automated test suites directly into the CI/CD pipeline and establishing strict criteria, or Quality Gates, that code must pass before advancing to the next stage. A quality gate acts as a critical checkpoint, automatically preventing defective or non-compliant code from ever reaching a production environment.
The core principle is to build confidence with every commit. By validating code against predefined quality standards at multiple levels, teams can drastically reduce the risk of deploying bugs, performance issues, or security vulnerabilities. Industry leaders like Google and Microsoft have institutionalized this approach, integrating extensive automated testing and quality gates into their global DevOps pipelines. This practice is a fundamental component of modern software deployment best practices, as it enforces quality and stability systematically.
Key Aspects of a Robust Testing Strategy
An effective testing strategy is multi-layered and integrated directly into the deployment workflow. It’s not just about running tests; it’s about making go/no-go decisions based on their outcomes. Quality gates formalize this decision-making process, ensuring that only high-quality code moves forward.
This strategy ensures that any issues are caught early, when they are cheapest and easiest to fix, rather than by users in production. It transforms quality assurance from a manual, end-of-cycle activity into a continuous, automated process that runs parallel to development.
Implementing Effective Quality Gates
Successfully integrating automated testing and quality gates requires a strategic and balanced approach to maintain both development velocity and product stability.
- Implement the Testing Pyramid: Structure your tests according to the testing pyramid model, focusing on a large base of fast, inexpensive unit tests, a smaller layer of integration tests, and a minimal number of slow, complex end-to-end (E2E) tests. This prioritizes rapid feedback.
- Set Realistic Quality Thresholds: Your quality gates should balance speed and safety. Define clear, measurable criteria such as minimum code coverage percentages, zero critical security vulnerabilities, and acceptable performance benchmarks. These thresholds should be strict but not so restrictive that they block all progress.
- Include Security and Performance Tests: Modern quality gates must go beyond functional correctness. Integrate static application security testing (SAST), dynamic application security testing (DAST), and load testing into your pipeline to catch security flaws and performance regressions before deployment.
- Regularly Review and Maintain Tests: Test suites are not “set it and forget it.” They are living code that requires regular maintenance. Periodically review tests to remove obsolete ones, refactor brittle ones, and ensure they remain relevant to the application’s evolving functionality.
For teams looking to deepen their knowledge, you can explore various techniques and tools in our comprehensive articles on automated testing. This commitment to automated quality assurance is what enables organizations to deploy with speed and confidence.
6. Rollback Strategy and Disaster Recovery
Even with the most rigorous testing, deployments can fail. A robust rollback strategy and disaster recovery plan are not signs of pessimism but hallmarks of a mature engineering culture. This practice ensures that teams can quickly and safely revert to a previously stable version when a deployment introduces critical bugs, performance degradation, or security vulnerabilities. Rollback strategies are predefined, automated procedures to undo a deployment, while disaster recovery (DR) encompasses a broader set of policies to restore service after a catastrophic failure.
The core principle is to minimize Mean Time to Recovery (MTTR), a critical metric for system reliability. A swift, predictable rollback is often the fastest way to restore service for users, allowing developers to diagnose the root cause in a less stressful, non-production environment. Engineering giants like Amazon Web Services and Google have built their reputations on reliability, which is heavily dependent on sophisticated, automated rollback and recovery systems. These are essential software deployment best practices because they provide a crucial safety net, reducing the risk associated with pushing new code.
Key Components of a Resilient Recovery Plan
An effective recovery plan is multifaceted, addressing both immediate deployment failures and larger-scale disasters. It integrates automated triggers with clear, human-driven procedures to ensure a rapid and orderly response to any incident. These components work together to protect user experience and maintain system integrity.
The plan must define the triggers for a rollback, the technical steps to execute it, and the communication protocols to keep stakeholders informed. It is a proactive measure that transforms a potential crisis into a manageable event.
Implementing Rollback and DR Effectively
Merely having a plan is insufficient; it must be actionable, tested, and automated wherever possible. This requires a strategic investment in both tooling and process.
- Implement Automated Health Checks: Configure your monitoring systems to track key health metrics like error rates, latency, and resource utilization. Set up automated triggers that initiate a rollback if these metrics cross predefined thresholds post-deployment.
- Use Immutable Deployments: Deployments should create new, immutable artifacts (like container images or server instances) rather than modifying existing ones. This simplifies rollbacks, as reverting is as simple as deploying the previous version’s artifact, eliminating state-related complexities.
- Maintain Detailed Runbooks: For scenarios that cannot be fully automated, maintain clear, step-by-step runbooks. These guides should detail the disaster recovery process, contact information for key personnel, and communication templates.
- Test Rollback Procedures Regularly: Routinely test your rollback mechanisms in a staging environment to ensure they work as expected. This builds team confidence and uncovers any process or tooling-related issues before a real incident occurs.
By integrating these practices, you can dramatically reduce downtime and protect your users from the impact of failed deployments. For teams looking to formalize their approach, you can find a deeper dive into creating a deployment rollback plan. This proactive stance is fundamental to building and maintaining resilient, trustworthy software.
7. Environment Parity and Configuration Management
A frequent source of deployment failures is the dreaded phrase, “But it worked on my machine.” This issue arises from subtle yet critical differences between development, staging, and production environments. Environment Parity is the practice of keeping these environments as identical as possible, spanning infrastructure, operating systems, dependencies, and system libraries. It is coupled with Configuration Management, which is the systematic handling of environment-specific settings like API keys, database credentials, and feature flags.
The core objective is to eliminate surprises during deployment by ensuring that code behaves predictably across its entire lifecycle. When an application is tested in a staging environment that mirrors production, the team gains high confidence that the production deployment will succeed. This practice is a crucial component of reliable software deployment best practices because it directly reduces deployment risk and accelerates debugging. Pioneers like Heroku, with their twelve-factor app methodology, have long advocated for this approach as foundational to scalable, modern applications.
Key Aspects of Environment Parity
Achieving true parity requires a deliberate focus on consistency across every layer of the application stack. This discipline ensures that what you test is what you ultimately deploy, minimizing environment-specific bugs that are often difficult and costly to resolve post-release.
The following are the core pillars of a strong environment parity strategy:
- Infrastructure: Using the same underlying infrastructure definitions (e.g., via Terraform or CloudFormation) for all environments.
- Dependencies: Ensuring identical versions of all libraries, packages, and services are used.
- Data: While production data is unique, staging environments should use realistic, production-like datasets.
- Configuration: Separating configuration from code and managing it externally.
This holistic approach builds a predictable and stable foundation for the entire software delivery pipeline, from the first line of code to the final user-facing release.
Implementing Parity and Configuration Effectively
Adopting this practice requires both the right tools and a disciplined development culture. The goal is to make consistency the path of least resistance.
- Use Containerization: Tools like Docker and Podman are game-changers for environment parity. By packaging your application and its dependencies into a container, you create a portable artifact that runs identically on a developer’s laptop, a staging server, or a production cluster.
- Implement Centralized Configuration Management: Utilize tools like HashiCorp Vault, AWS Parameter Store, or Azure Key Vault to store and manage configurations centrally. This prevents secrets from being hardcoded in your repository and allows for secure, audited access.
- Separate Config from Code: Adhere to the twelve-factor app principle of storing configuration in environment variables. This practice decouples your application build from its environment-specific settings, making the same deployment artifact usable across dev, staging, and production.
- Regularly Audit and Sync Environments: Automate regular checks to detect “drift” where environments have diverged. Use infrastructure-as-code tools to enforce consistency and automatically correct any discrepancies discovered.
By focusing on these strategies, teams can significantly improve the reliability of their deployments. To explore more advanced strategies for building consistent and automated workflows, you can find a wealth of information in these articles about DevOps best practices on codepushgo.com. This commitment is essential for teams aiming to build robust and predictable software delivery systems.
7 Key Software Deployment Practices Compared
| Item | Implementation Complexity 🔄 | Resource Requirements ⚡ | Expected Outcomes 📊 | Ideal Use Cases 💡 | Key Advantages ⭐ |
|---|---|---|---|---|---|
| Continuous Integration/Continuous Deployment (CI/CD) | High – requires pipeline setup and automation skills | Moderate to High – depends on automation and testing infrastructure | Frequent, reliable software updates with early integration issue detection | Teams needing fast, automated build-test-deploy cycles | Faster time to market, improved code quality, reduced errors |
| Blue-Green Deployment | Medium – managing two identical environments | High – double infrastructure cost | Zero-downtime deployments with instant rollback | Critical production environments needing uninterrupted service | Zero downtime, instant rollback, reduced deployment risk |
| Canary Deployment | Medium to High – gradual rollout and monitoring setup | Moderate – requires monitoring and traffic control tools | Controlled, progressive releases minimizing user impact | Large user bases requiring staged feature rollouts | Early issue detection, reduced blast radius, data-driven releases |
| Infrastructure as Code (IaC) | High – requires learning IaC tools and writing code | Moderate – automation significantly reduces manual resources | Consistent, reproducible infrastructure with version control | Teams managing cloud infrastructure or complex environments | Environment consistency, faster provisioning, change tracking |
| Automated Testing and Quality Gates | High – building comprehensive test suites and quality metrics | Moderate to High – test automation infrastructure | Early bug detection, enforced quality before deployment | Dev teams focusing on software reliability and early feedback | Consistent quality standards, reduced manual testing effort |
| Rollback Strategy and Disaster Recovery | Medium to High – complex versioning and automation | Moderate – storage and runbook preparation | Minimized downtime, fast recovery from failed deployments | Environments where stability and incident recovery are critical | Reduced MTTR, incident response improvement, data loss protection |
| Environment Parity and Configuration Management | Medium – configuration tools and environmental setup | Moderate to High – requires duplicated environments | Predictable deployments with fewer environment-specific issues | Teams with multiple deployment stages requiring consistency | Reduced deployment issues, improved debugging, better security |
Future-Proofing Your Deployments: Integrating Modern Practices
Mastering modern software deployment is an ongoing journey, not a final destination. The landscape of software delivery is in a state of perpetual evolution, demanding that teams remain agile, security-conscious, and strategically proactive. The seven core pillars we have explored in this guide are not just isolated tactics; they are the foundational components of a resilient, high-velocity delivery ecosystem. By weaving these principles together, you create a powerful synergy that transforms your release process from a high-stakes, anxiety-inducing event into a predictable, low-risk, and strategic business advantage.
The shift from manual, error-prone deployments to a streamlined, automated workflow is no longer a luxury but a competitive necessity. Adopting these software deployment best practices fundamentally changes how your organization operates, enabling faster innovation, dramatically improving product quality, and ultimately delivering a superior and more reliable user experience.
From Individual Tactics to a Holistic Strategy
It is crucial to view these practices not as a checklist to be completed but as interconnected elements of a unified strategy. A truly effective deployment pipeline is greater than the sum of its parts.
- CI/CD pipelines (Item 1) provide the automated backbone for your entire process.
- Infrastructure as Code (IaC) (Item 4) ensures your environments are consistent and reproducible, which is essential for the reliability of your pipeline.
- Environment Parity (Item 7) eliminates the dreaded “it works on my machine” problem, making deployments predictable across staging and production.
- Automated Testing and Quality Gates (Item 5) are the gatekeepers of quality, preventing bugs from ever reaching your users and building confidence in every release.
This integrated approach creates a virtuous cycle. When your infrastructure is codified and your environments are identical, your automated tests yield far more reliable signals. This confidence, in turn, empowers you to deploy more frequently and leverage sophisticated strategies like Blue-Green and Canary releases.
The Power of Controlled, Phased Rollouts
Perhaps the most significant strategic shift is moving away from “big bang” deployments. Advanced techniques like Blue-Green Deployment (Item 2) and Canary Deployment (Item 3) are central to modern risk management. They allow you to de-risk releases by exposing new code to a small subset of users first, monitoring for issues in a real-world setting before committing to a full rollout.
This capability, combined with a robust Rollback Strategy (Item 6), transforms potential disasters into minor, manageable incidents. The goal is not to never make a mistake; it is to build a system so resilient that mistakes have a minimal blast radius and can be corrected almost instantaneously. This resilience is the hallmark of a mature DevOps culture and is a direct result of implementing these advanced software deployment best practices.
Bridging the Gap in Mobile Deployments
For development teams in the mobile space, especially those building with React Native, these principles take on a unique and often more challenging dimension. The inherent delay and uncertainty of app store review cycles present a significant bottleneck, one that traditional web deployment strategies simply cannot address. This friction can cripple a team’s ability to respond quickly to critical bugs or iterate on user feedback.
This is precisely where specialized tools become indispensable. The challenge of mobile delivery requires a solution that embraces the agility of CI/CD while navigating the constraints of the mobile ecosystem. By integrating a secure Over-the-Air (OTA) update mechanism, you can apply the very same principles of continuous delivery and phased rollouts directly to your mobile applications. You can push critical bug fixes, UI tweaks, and feature updates in minutes, not days or weeks, bypassing the app store review process for bundled code changes. This brings the speed and control of web deployments to the native mobile world, ensuring your entire software portfolio benefits from agile, reliable, and secure release cycles.
If you’re ready to bring these powerful OTA capabilities to your React Native applications, it’s time to supercharge your mobile deployment strategy. See how CodePushGo can integrate seamlessly with your existing CI/CD workflow, enabling you to implement canary releases, instant rollbacks, and secure hotfixes with ease.


